|






 |  |

| Aeronautica | Comunicatii | Drept | Informatica | Nutritie | Sociologie |
| Tehnica mecanica |
Baze de date
|
|
Qdidactic » stiinta & tehnica » informatica » baze de date Modelul relational de baze de date - definirea modelului relationalarea bazelor de date relationale |
Modelul relational de baze de date - definirea modelului relationalarea bazelor de date relationale
Modelul relational
Bazele de date relationale sunt declarative, adica ele elimina sarcina declararii modului de accesare a datelor, aplicatiile concentrandu-se asupra a ceea ce au nevoie din bazele de date.
Un model relational de baze de date cuprinde trei componente principale:
-structura datelor prin definirea unor domenii(valori atomice) si a relatiilor n-are(atribute, tupluri, chei primare, etc.);
-integritatea datelor prin impunerea unor restrictii;
-prelucrarea datelor prin operatii din algebra relationala sau calculul relational.
1.Definirea modelului relational
Modelul relational se bazeaza pe notiunea matematica de relatie, asa cum este definita in teoria multimilor, ca o submultime a produsului cartezian a unei liste finite de multimi numite domenii. Elementele unei relatii se numesc tupluri, iar numarul de domenii din produsul cartezian se numeste aritatea relatiei. Spre exemplu, a1, a2,,ak cu ai din Di pentru orice i=1,,k reprezinta un tuplu al unei relatii aritate k, in care ai este cel de-al i-lea element al tuplului.
De obicei relatiile sunt reprezentate sub forma unor tabele in care fiecare rand reprezinta un tuplu si fiecare coloana reprezinta valorile tuplurilor dintr-un domeniu dat al produsului cartezian.
In reprezentarea sub forma de tabel a unei relatii, coloanelor si domeniilor corespunzatoare lor li se asociaza nume intitulate atribute. Multimea numelor atributelor unei relatii se numeste schema relationala. Daca relatia numita R are atributele A1,A2,,Ak, atunci schema relationala se noteaza R(A1,A2,,Ak).
Relatiile mai pot fi definite ca o multime de functii definite pe o multime de atribute cu valori in reuniunea unor domenii, cu restrictia ca valoarea corespunzatoare fiecarui atribut sa se afle in domeniul asociat acelui atribut.
Trecerea de la un mod de definire al relatiei la celalalt se face relativ simplu. O relatie in sensul de multime se transforma intr-o relatie in sensul de functii asociind fiecarui domeniu D1,D2,,Dk al produsului cartezian cate un nume de atribut A1,A2,,Ak si definind pentru fiecare tuplu ti=(ai1,ai2,,aik) functia fi cu fi(Aj)=aij, j=1,,k. Multimea acestor functii formeaza o relatie in sensul celei de a doua definitii. Trecerea inversa se face impunand o relatie de ordine totala pe multimea atributelor si asociind fiecarei functii tuplul obtinut din valorile functiei respective, in ordinea corespunzatoare a atributelor.
Din punctul de vedere al bazelor de date, cea de a doua definitie este de preferat deoarece permite prelucrarea informatiilor corespunzatoare unui atribut fara a cunoaste pozitia acelui atribut in relatie. Aceasta asigura o mai mare independenta de reprezentare a datelor, atat la nivel logic cat si la nivel fizic, putandu-se efectua modificari in definirea structurilor fara afectarea altor nuvele.
Pentru relatiile ce constituie o baza de date se fac diferite presupuneri initiale cum ar fi: neexistenta unor tupluri duplicate, neaparitia intr-o ordine data a tuplurilor, neaparitia intr-o ordine data a atributelor, posibilitatea ca toate atributele sa aiba numai valori atomice, etc.
Se numeste candidat de cheie a unei relatii R coloana sau multimea de coloane din R pentru care valorile corespunzatoare din oricare doua tupluri nu coincid, deci identifica tuplurile din relatia respectiva, si nu contin strict o submultime de coloane cu aceasta proprietate. Pentru fiecare relatie se alege un candidat de cheie care se numeste cheie primara a relatiei. Tuplurile unei relatii nu pot sa contina valoarea nula in coloane ce apartin cheii primare. Eventualii candidati de cheie, diferiti de cheia primara, se numesc chei alternante. Se numeste cheie straina o coloana sau o multime de coloane a unei relatii Rl ale carei/caror valori, daca nu sunt nule, coincid cu valori ale unei chei primare dintr-o relatie R nu neaparat distincta de Rl.
Multimea tuturor schemelor relationale corespunzatoare unei aplicatii se numeste schema bazei de date relationale, iar continutul curent al relatiilor la un moment dat se numeste baza de date relationala.
In modelul relational, entitatile sunt reprezentate sub forma de relatii in care schema relationala contine toate atributele entitatii si fiecare tuplu al relatiei corespunzatoare unui element al entitatii. La atributele entitatii se pot adauga in relatie si eventuale atribute suplimentare utilizate pentru exprimarea relatiilor intre entitati. O relatie intre entitatile E1,E2,,Ek se reprezinta ca o relatie in care fiecare tuplu (e1,e2,,ek) este un element al relatiei initiale, ei fiind o cheie pentru relatia Ei asociata.
Cele mai multe cereri privesc determinarea unor informatii cu anumite proprietati, iar raspunsul posibil este o relatie care descrie toate elementele cu aceste proprietati. Modul de reprezentare al raspunsului depinde de interfata dintre SGBD si utilizator.
2.Proiectarea bazelor de date relationale
Proiectarea unei baze de date poate fi realizata intr-o multime de moduri si dupa nenumarate teorii. Aceste teorii ajuta la gruparea tuplelor pe domenii si la alegerea atributelor celor mai adecvate. Oportunitatea realizarii schemelor relationale poate fi raportata la doua nivele:
1. nivelul logic care se refera la modul in care un utilizator interpreteaza o schema relationala si intelege atributele ei. O relatie buna ajuta utilizatorul sa inteleaga sensul fiecarui atribut, rolul datelor din tuplele relatiei si sa poata formula interogari corecte;
2. nivelul de manipulare sau de manevrare al datelor se refera la modul in care tuplele din relatia de baza sunt stocate si actualizate. Acest nivel se aplica doar relatiilor de baza, adica fisierelor, spre deosebire de primul nivel care se poate aplica si vederilor. Vederile sunt constructii asemanatoare fisierelor, dar care exista numai atata timp cat sunt active.
Pentru a proiecta o baza de date trebuie s fie cunoscute:
semantica atributelor;
reducerea valorilor redundante in tuple;
reducerea valorilor NULL in tuple;
respingerea tuplelor eronate.
Fiecare atribut al unei relatii are un nume, deci un anumit inteles. Acest inteles sau semantica, specifica cum se pot interpreta valorile atributelor memorate in tuple sau cum valorile atributelor sunt legate unele de altele. Se considera o baza de date numita Companie cu urmatoarele relatii:
Salariat
|
NUME |
MATRICOL |
DATAN |
ADRESA |
DNUMAR |
|
|
|
|
|
|
Depart
|
DNUME |
DNUMAR |
DMGRMAT |
|
|
|
|
Deplocatie
|
DNUMAR |
DLOCATIE |
|
|
|
Proiect
|
PNUME |
PNUMAR |
PLOCATIE |
DNUM |
|
|
|
|
|
Lucratori
|
MATRICOL |
PNUMAR |
ORA |
|
|
|
|
Intelesul pentru relatia salariat este simplu. Fiecare tupla reprezinta un salariat cu valorile specifice atributelor considerate: nume, matricol, ziua de nastere, adresa, numarul departamentului in care lucreaza. Acest camp este cheia externa care reprezinta legatura implicita intre relatia Salariat si Depart. Semantica relatiei depart este: fiecare tupla reprezinta entitatea departament, cu nume si numar. Atributul DMGRMAT reprezinta numarul matricol al managerului departamentului. Semantica relatiei DEPLOCATIE reprezinta numarul departamentului si localitatea in care se gaseste departamentul. Semantica relatiei Proiect este: fiecare tupla reprezinta entitatea proiect cu numele proiectului, numarul proiectului, localitatea in care se realizeaza si numarul departamentului care gestioneaza proiectul. Relatia lucratori reprezinta numarul de ore lucrat de un proiectant la un anumit proiect. Proiectantul este individualizat prin MATRICOL, iar proiectul prin numarul proiectului (PNUMAR). Putem formula acum prima regula de ghidare in proiectarea bazelor de date relationale:
Proiectarea relatiei sa se faca astfel incat sa fie usor de explicat intelesul acesteia.
Aceasta inseamna ca nu este recomandabil sa se amestece atribute de la multiple tipuri de entitati intr-o singura relatie.
Se considera relatiile:
Salariat dep
|
NUME |
MATR |
DATA_N |
ADRESA |
DNUME |
DNUMAR |
DMGRSSN |
|
|
|
|
|
|
|
|
Salariat_pro
|
MATR |
PNUMAR |
ORE |
NUME |
PNUME |
PLOCALIT |
|
|
|
|
|
|
|
Aceste doua relatii sunt destul de clare din punct de vedere semantic, dar ele amesteca atribute de angajati cu atribute de departamente, respectiv atribute de angajati cu atribute despre proiecte, contravenind primei instructiuni de ghidare in proiectare. Acest amalgam de atribute poate fi un punct de plecare in proiectare, dar ulterior el va genera probleme destul de grave in care relatile sunt folosite ca relatii de baza de date.
Pentru a avea o buna relatie este necesara minimizarea spatiului pe care aceasta il ocupa. Gruparea atributelor intr-o relatieare un rol determinant in ce priveste spatiul ocupat. De obicei, relatiile care sunt formate din atribute ce se refera la o singura entitate ocupa un spatiu mai mic decat cele care se refera la mai multe entitati.
O problema complexa care apare este problema actualizarii anomaliilor. Acestea se impart in trei categorii:
- anomalii de inserare;
- anomalii la stergerea tuplelor;
- anomalii la modificarea tuplelor.
Anomaliile de inserare a tuplelor pot fi de doua tipuri:
1. relatia contine mai multe entitati si modificarea unei entitati trebuie sa modifice corect si celelate entitati. Daca se considera relatia Salariat_dep, daca se introduc date despre un salariat nou, trebuie avut grija sa se introduca corect datele despre departament.
2. relatia contine mai multe entitati si una sau mai multe entitati nu contin nici un fel de informatie. Considerand relatia Salariat_dep este dificil de a insera un departament nou care nu are angajati in relatie. Singura solutie este de a pune valoarea NULL in atributele referitoare la angajat, doar ca aceasta contravine faptului ca atributul MATR este considerat cheie deci nu accepta valori NULL.
|
Aceste anomalii de inserare nu apazt in cazul in care se
considera cele doua relatii Salariat si Depart.
Anomalii de stergere pot sa apara la relatiile care contin atribute ce se refera la mai multe entitati.
Anomalii la modificarea tuplelor apar tot in cazul relatiilor care contin informatii despre mai multe entitati. Considerand relatia Salariat_dep, modificarea unor date despre un anumit departament implica modificarea acestor informatii in toate tuplele care contin salariati ce lucreaza in acel departament.
Se poate formula a doua regula de ghidare pentru proiectarea relatiilor:
O relatie se proiecteaza astfel incat sa nu apara greseli de inserare, stergere sau modificare.
In anumite cazuri se pot grupa o multime de atribute intr-o relatie mai mare. Daca mai multe astfel de atribute nu se aplica pentru toate tuplele din relatie, vor apare o multime de NULL-uri in relatie. Aceasta poate insemna pierderea de spatiu la nivel de stocare si ridia probleme in intelegerea atributelor si a operatiilor la nivel logic. O alta problema este cea a contabilizarii valorii NULL daca se folosesc functiile agregat cum ar fi COUNT contorizeaza tuplele din relatie in unele implementari SGBD sau SUM calculeaza suma valorilor din domeniul unui atribut. Valoarea NULL are mai multe intelesuri:
atributul nu se aplica la acesta tupla;
valoarea atribututlui pentru aceasta tupla este necunoscuta;
valoarea este cunoscuta, dar este absenta; aceasta inseamna ca nu a fost inca inregistrata.
Avand aceeasi reprezentare pentru NULL, intelesul sau este compromis. Rezulta a treia regula de ghidare:
Sa se evite pe cat posibil plasarea atributelor care au valoarea NULL intr-o relatie.
In cazul in care sunt doua sau mai multe relatii cu un anumit numar de tuple, este posibil ca, prin legarea celor doua sau mai multe relatii sa rezulte relatii cu mai multe tuple decat cele initiale. Tuplele care apar in plus se numesc tuple gresite sau false. Rezulta a patra regula de ghidare:
Proiectarea relatiilor trbuie sa se faca astfel incat sa poata fi legate prin conditii de egalitate ale atributelor cheie primara sau cheie externa, cu alte relatii, intr-un mod care sa garanteze ca nu vor fi generate tuple false sau gresite.
Unul dintre conceptele cele mai importante in proiectarea bazelor de date relationale este dependenta functionala. Se presupune ca schema bazei de date relationale are atributele: R=.
O dependenta functionala notata X Y intre doua multimi de atribute X si Y, care sunt submultimi ale schemei relationale R, specifica o restrictie pe un numar de tuple r a lui R. restrictia exprima ca pentru oricare doua tuple t1 si t2 din r cu t1[X]=t2 [X] putem avea t1 [Y]=t2 [Y].
Aceasta inseamna ca valorile multimii de atribute Y depind de valorile multimii de atribute X. Se mai spune ca Y este dependent functional de X. Daca se noteaza dependenta functionala cu FD, atributele X se numesc partea stanga a lui FD iar atributele Y se numesc partea dreapta a lui FD.
Se poate da si o alta definitie a dependentei functionale:
In schema relationala R, multimea de atribute X determina functional pe Y daca si numai daca de cate ori doua tuple ale lui r(R) sunt egale pentru submultimea de atribute X a lui R, atunci ele sunt egale si petru submultimea de atribute Y a lui R.
In cazul in care X este cheie candidat a lui R, inseamna ca dependenta functionala X Y exista pentru orice submultime Y a lui R. daca dependenta functionala X Y exista, aceasta nu implica existenta dependentei functionale Y X.
Dependenta functionala este o proprietate a intelesului semanticii atributelor intr-o relatie R. Conceptul de folosire al dependentei functionale este de a descrie relatia R specificand constrangerile pe atributele sale care trebuie avute in vedere tot timpul.
Daca se considera relatia Salariat_pro, se pot defini urmatoarele dependente functionale:
- MATR NUME
- PNUMAR
- ORA
Aceste dependente functionale specifica:
valoarea unui numar matricoldetermina individual numele unui salariat;
valoarea numarului de proiect determina unic numele proiectului si localitatea in care se realizeaza proiectul;
combinatia dintre matricol si numarul de proiect determina unic numarul de ore lucrat de angajat intr-o saptamana.
Dependenta functionala este o proprietate a relatiei R si nu a restrictiei r a lui R. Conceptul nu se poate implementa automat, ci se implementeaza numai in urma cunoasterii precise a semanticii atributelor.
Intr-o relatie se pot defini mai multe dependente functionale. Multimea tuturor dependentelor functionale se noteaza cu F+ si se numeste inchiderea lui F. daca consideram relatia Salariat_dep, putem defini urmatoarele dependente functionale:
- MATR
- DNUMAR
- MATR
- MATR MATR
- DNUMAR DNUME
Inchiderea F+ reprezinta multimea tuturordependentelor functionale care pot fi deduse din R. Daca se noteaza cu F multimea dependentelor functionale se poate folosi notatia F=X Y pentru a nota ca dependenta functionala X Y este dedusa din multimea de dependente functionale F sau F deduce pe X Y.
Se va nota:
FD Z=XY Z
FD =XYZ UV
Cele sase reguli de deductie ale dependentei functionale sunt:
1. reflexiva, daca X Y atunci X Y
2. extindere, daca =XZ YZ
3. tranzitiva, daca =X Z
4. descompunere, daca =X Y
5. de unire, daca =X YZ
6. pseudotranzitiva, daca =WX Z
Regula reflexiva arata ca o multime de atribute este totdeauna determinata de ea insusi.
Regula de extindere arata ca adaugand la stanga si la dreapta unei dependente aceeasi cantitate rezulta o alta dependenta.
Regula tranzitiva arata ca daca avem doua dependente functionale in care sunt implicate trei multimi de atribute, atunci exista si a treia dependenta functionala intre atribute.
Regula de descompunere arata ca o dependenta functionala se poate diviza in mai multe dependente functionale.
In general, setul de dependente complet F+ (inchiderea lui F) poate fi determinat folosind doar primele trei reguli, numite si regulile de deductie ale lui Armstrong.
Pentru a descoperi dependentele functionale dintr-o relatie R se pot determina mai intai dependentele functionale F pe baza semanticii atributelor relatiei R. Se pot folosi regulile de deductie ale lui Armstrong pentru a deduce dependentele functionale aditionale. Dependentele functionale aditionale se afla determinand mai intai fiecare multime de atribute X ce apar la stanga lui F, apoi cu regulile 1-3 se determina setul de atribute dependent de X. astfel, pentru fiecare multime de atribute X se determina inchiderea X+ de atribute care sunt dependente functional de X.
Echivalenta a doua multimi de dependente functionale E+ si F+ se noteaza: E+=F+ si inseamna ca fiecare FD din E+ poate fi dedusa din F+ si fiecare FD din F+ poate fi dedusa din E+. o multime de dependente functionale este minima daca:
- fiecare dependenta are un singur atribut la mana dreapta;
- avand o multime de dependente echivalente cu F, nu se poate muta nici o dependenta din F;
- nu se poate inlocui nici o dependenta X A in F cu o dependenta Y A, unde Y este o submultime a lui X si are o serie de dependente care sunt echivalente cu F.
Forma normala sau normalizarea bazelor de date relationale este un alt instrument deosebit de important in proiectarea bazelor de date. Normalizarea este un proces prin care se verifica daca relatia satisface anumite conditii. In cazul in care nu sunt indeplinite respectivele conditii relatia se descompune, prin distribuirea atributelor in una sau mai multe relatii mai mici care indeplinesc conditiile cerute. Unul dintre obiectivele procesului de normalizare este ca relatia sa aiba o proiectare buna, sa nu permita aparitia anomaliilor. Formele normale determina proiectantul bazelor de date relationale sa realizeze:
o schita formala pentru analizarea relatiei bazata pe cheile ei si o lista cu dependentele functionale dintre atribute;
o serie de teste ce pot fi facute pe relatiile individuale astfel incat baza de date sa poata fi normalizata la orice grad.
Procesul de normalizare nu se desfasoara independent de celelalte cerinte asupra proiectarii bazelor de date prezentate in paragrafele anterioare. Divizarea unei relatii in mai multe relatii functie de dependentele functionale ale atributelor este influentata de doi factori:
1. unirea fara pierderi sau nonasociativa a doua sau mai multe relatii sa garanteze faptul ca nu apar tuple eronate;
2. dependentele functionale care apar in relatia initiala trebuie sa se pastreze si in relatiile rezultate prin procesul de normalizare.
O supercheie a unei relatii R= este o multime de atribute S R cu proprietatea ca in multimea r a tuplelor nu exista doua tuple t1 si t2 astfel incat t1 [S]=t2 [S]. Diferenta dintre cheie si supercheieconsta in faptul ca o cheie are un singur atribut iar o supercheie are mai multe atribute. O relatie are in general o schema primara in care sunt definite cheia primara si cheile secundare. Un atribut se numeste atribut principal daca face parte dintr-o cheie a relatiei R.
Normalizarea consta in faptul ca fiecare relatie trebuie sa contina date cu un anumit sens (entitate).
Daca relatia contine date referitoare la mai multe entitati, atunci ea trebuie sparta in mai multe relatii. Relatiile pot fi clasificate in functie de anomaliile la care sunt vulnerabile. Clasele de relatii si tehnicile folosite pentru prevenirea anomaliilor se numesc forme normale.
Prima forma normala se identifica cu definitia relatiei. Ea a fost definita pentru a nu recunoaste atribute multinivel, atribute compuse si combinatiile lor.
Prima forma normala poate fi definita:
Domeniile atributelor trebuie sa includa doar valori atomice, indivizibile, iar valorile tuplelor trebuie sa fie distincte pe tot domeniul. Nu sunt permise doua tuple cu aceeasi valoare.
Prima forma normala nu recunoaste relatii in relatii, singura valoare permisa pentru un atribut fiind valoarea atomica sau indivizibila.
Atributul poate fi privit ca:
domeniu format din valori atomice dar cu unele tuple care contin multimi ale acestora;
domeniul atributelor nu este atomic.
Se considera:
|
DEPARTAMENT |
DMGRMATR |
DNUMAR |
DLOCALITATE |
|
Cercetare |
5000 |
5 |
Arad, Sibiu, Alba |
|
Administrativ |
4000 |
4 |
Deva |
|
Tehnic |
1000 |
1 |
Brasov |
Daca se considera prima interpretare DMGRMATR* DLOCALITATE, adica DLOCALITATE nu este dependent functional de Dmgrmatr. Pentru cea de a doua interpretare DMGRMATR DLOCALITATE, adica Dlocalitate nu este dependent functional de matricol, deoarece fiecare multime de valori este considerata ca un singur membru al domeniului atributului. DMGRMATReste numarul matricol al managerului departamentului. In ambele cazuri, relatia nu este in prima forma normala. Se observa ca relatia contine atribute referitoare la doua entitati:numele departamentului si localitatea in care acesta se gaseste. Daca se sterge o tupla care contine o anumita localitate, se sterg informatii referitoare la numele departamentului. Pentru ca relatia sa fie in prima forma normala, aceasta se sparge in doua relatii:
DEPART
|
DEPARTAMENT |
DNUMAR |
DMGRMATR |
|
|
|
|
D_LOC
|
DNUMAR |
DLOCALITATE |
|
|
|
In acest caz, in relatia D_LOC, valorile domeniului DLOCALITATE vor fi indivizibile. Cheia primara in acesta relatie este o combinatie inre cele doua atribute, pentru fiecare locatie existand cate o tupla primara.
Prima forma normala nu permite relatii imbricate, adica acele relatii care admit atribute compuse. Relatiile se numesc imbricate pentru ca fiecare tupla admite o alta relatie in interiorul sau. Exmplu de astfel de relatie:
Sal_pro
|
MATRICOL |
N_SALARIAT |
PROIECT |
|
|
|
|
P_NUME |
ORE_L |
|
|
|
|
|
MATRICOL=numar matricol al salariatului;
N_SALARIAT=numele salariatului;
P_NUME=numele proiectului;
ORE_L=ore lucrate la proiect de un anumit salariat;
PROIECT=atribut cu valori multiple.
Relatia SAL_PRO contine in interiorul sau relatia PROIECT, care are ca atribute numele proiectului si numarul de ore lucrate la acesta de catre un salariat.
Relatiile imbricate se mai pot nota:
SAL_PRO=}
Normalizarea relatiei SAL_PRO in prima forma normala se realizeaza spargand relatia existenta in doua relatii, pastrand cheia principala in amandoua relatiile. Presupunand ca atributul MATRICOL este cheie principala, relatiile rezultate vor fi:
Sal_pro1
|
MATRICOL |
N_SALARIAT |
|
|
|
Sal_pro2
|
MATRICOL |
P_NUME |
ORE_L |
|
|
|
|
In cazul in care sunt mai multe nivele de imbricare, aceasta procedura de transformarea unei relatii imbricate in mai multe relatii care se afla in prima forma normala poate fi aplicata recursiv.
O relatie se gaseste in a doua forma normala daca cheia primara este o supercheie si oricare atribut noncheie al relatiei depinde functional de toata cheia. In cazul in care cheia primara este formata dintr-un singur atribut, relatia se gaseste in a doua forma normala.
Se considera o aplicatie in care se urmareste evidentierea destinatiei proiectelor in anumite sali. Exista relatia Sala formata din atributele:
MATRICOL = numar matricol salariat
N_proiect = nume proiect
Ore_l = ore lucrate de un salariat la un anumit proiect
Relatia are tuplele:
|
Matricol |
N_proiect |
Ore_l |
|
12 |
A |
23 |
|
11 |
B |
34 |
|
2 |
A |
67 |
|
5 |
A |
2 |
Cheia relatiei este formata din atributele Matricol+N_proiect. Atributul Ore_l depinde functional de toata cheia si nu depinde de functional de atributele din care este formata cheia.
O relatie se gaseste in cea de a treia forma normala daca se gaseste in a doua forma normala si relatia nu prezinta dependente functionale tranzitive.
Se considera un exemplu de relatie care prezinta dependente functionale tranzitive:
|
Nr buletin |
Nume hotel |
Taxa cazare |
|
|
|
|
Cheia relatiei este Nr_buletin. In relatie exista urmtoarele dependente functionale:
Nr_buletin nume hotel;
Nume_hotel Taxa_cazare.
Tdependenta functionala: Nr_buletin Taxa_cazare.
Aceasta dependenta functionala rezultata conform regulii trei de deducere a dependentelor functionale este o dependenta functionala tranzitiva. In aceasta relatie apare o anomalie in sensul in care, daca se sterge o inregistrare cu un anumit numar de buletin, se sterge si informatia referitoare la taxa de cazare perceputa la un hotel. Petru a elimina aceasta anomalie, este necesar sa se sparga relatia in doua relatii:
|
Nr_buletin |
Nume_hotel |
|
|
|
|
|
|
|
|
Nume_hotel |
Taxa_cazare |
||
|
|
|
||
Relatia Sal considerata a fi in a doua forma normala este si in a treia forma normala pentru ca in relatie nu exista dependente functionale tranzitive. O relatie in atreia forma normala mai poate fi definita:
O relatie se gaseste in a treia forma normala daca fiecare atribut neprincipal al lui R este:
-dependent functional de fiecare cheie din relatie;
-nu este dependent tranzitiv de fiecare cheie din relatia considerata.
In afara acestor trei forme normale mai exista forma normala Boyce-Codd care este o forma mai stricta a cele de a treia forme normale:
O relatie R se afla in forma normala Boyce-Codd daca ori de cate ori o dependenta functionala X A exista in R, atunci X este supercheie a lui R.
Majoritatea relatiilor care sunt in a treia forma normala sunt si in forma Boyce-Codd. Doar daca in relatia R exista dependenta functionala X A, cu X care nu este supercheie si A atribut principal, atunci R este in a treia forma normala si nu este in forma normala Boyce-Codd. Relatiile care se gasesc in forma normala Boyce-Codd sunt cele mai performante.
Mai exista forma normala definita de Fagin care se mai numeste forma normala domeniu-cheie:
O relatie se gaseste in forma normala domeniu-cheie daca fiecare constrangere impusa relatiei de catre proiectant va deveni o consecinta logica a modului in care s-au definit cheile si domeniile relatiei, deci conditiile initiale devin consecinte ale definirii relatiei.
3. Scheme relationale
O baza de date este formata dintr-o colectie de date si dintr-un software necesar pentru controlul accesului la acestea. Toate acestea sunt cunoscute sub numele de sistem de gestiune al bazelor de date (SGBD). Un SGBD indeplineste urmatoarele functii:
-stocarea, regasirea si actualizarea datelor;
-posibilitatea accesarii informatiilor de catre mai multi utilizatori;
-posibilitati de parolare si criptare a bazelor de date;
-masuri de protejare a informatiei.
O baza de date care se bazeaza pe modelul relational este gandita ca o colectie de tabele bidimensionale numite relatii. Fiecare coloana a tabelului poarta denumirea de atribut sau camp. Fiecare linie a tabelului este definita prin numele relatiei si numele atributului, ea purtand denumirea de tupla, inregistrare sau articol. Atributul poate lua o serie de valori indivizibile, valori ce constituie domeniul atributului. In functie de domeniu, datele pot avea un anumit tip: logic, numeric, caracter, data calendaristica, etc. Datele pot avea si o anumita forma de prezentare, adica un format. Rezulta ca atributul unei relatii se defineste prin: domeniu, tip de data, format.
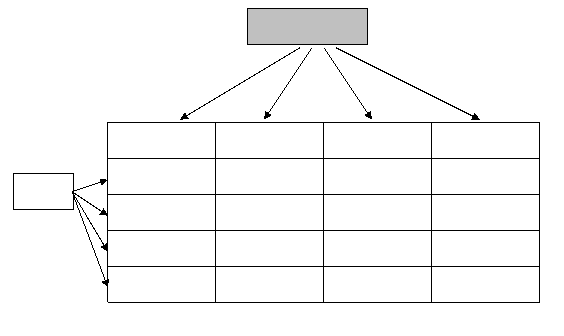
Atribute
Nume relatie
Student
NumePrenume Varsta Grupa
ArsinGheorghe 21 221
Tuple
Bucur Alexandru 20211
Olteanu Ionut-Teodor 20213
Popoiu Ileana-Carmen21 211
O schema relationala se noteaza:
R(A1, A2,, An)
Si este o multime de atribute . Domeniul atributului se noteaza prin dom(Ai). Rangul unei relatii este dat de numarul de atribute din cadrul relatiei. O relatie r(R) din schema relationala R(A1, A2, , An) poate fi definita ca multimea de tuple t1, t2, , tk. fiecare a i-a tupla este definita ca o multime de valori ordonate in ordinea de creare a atributelor tI=<V1, V2, , Vn>. fiecare valoare Vi cu 1≤i≤n este element al domeniului atributului Ai sau are valoarea NULL. Deci tupla este o linie, atributul este o coloana si specifica prin numele sau rolul valorilor dintr-o coloana. Valoarea NULL reprezinta un atribut a carui valoareeste necunoscuta sau nu exista pentru anumite tuple.
Cardinalitatea unui domeniu este definita prin numarul de tuple al produsului cartezian:
D dom(A1) dom(A2) dom(An)
O tupla mai poate fi definita si ca reuniunea domeniilor unei relatii:
D=dom(A1) dom(A2) dom(An)
Conform acestei definitii, tupla poate fi considerata ca o multime de perechi de valori(atribut, valoare).
In cadrul unei relatii, tuplele nu sunt ordonate. Datorita faptului ca fiecare tupla este un element al unei multimi, fiecare tupla este considerata ca o valoare unica (atomica). Deci, in cadrul unei relatii avem tuple distincte, altfel spus, setul de atribute corespunzatoare unei tuple trebuie sa fie diferit. Daca notam multimea atributelor corespunzatoare unei tuple Sk, pentru doua tuple distincte din cadrul unei relatii avem:
t1(Sk)≠t2(Sk)
Valoarea unei tuple este considerata indivizibila, atributele multinivel sau compuse fiind interzise. Un exemplu de atribut compus este prezentat in tabelul urmator:
|
N_ATRIB1 |
N_ATRIB2 |
N_ATRIB 3 |
|
|
NA_3_1 |
NA_3_2 |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Atributul N_atrib3 este formata din atributele Na_3_1 si Na_3_2. Aceasta restrictie este cercetata in prezent in sensul introducerii notiunii de relatie imbricata, deci atributul compus este simulat prin doua sau mai multe relatii care pornesc una din cealalta.
Daca relatia este implementata ca fisier atunci sunt permise tuple duplicat (cu aceeasi valoare) in cadrul unei relatii. Tot in acest caz, tuplele pot fi ordonate dupa valoarea unui atribut sau dupa valoarea mai multor atribute. Daca domeniul unui atribut contine doar valori distincte, acest atribut se numeste cheie. Ca si cheie a unui fisier pot fi alese si mai multe atribute, caz in care acestea se numesc supercheie. De obicei, pentru un fisier se alege o cheoie care poarta denumirea de cheie primara. Celelalte atribute sau combinatii de atribute, care au in domeniu valori distincte, poarta denumirea de chei candidat. Faptul ca o multime de atributepot fi o cheie este o proprietate a schemei relationale. In general, o schema relationala poate avea mai multe chei. Oricare din cheile candidat poate fi aleasa ca si cheie primara.
4.Scheme de baze de date relationale
O baza de date relationala contine mai multe relatii. O schema pentru o baza e date S contine o multime de scheme relationale:
S=
Si o multime de constrangeri de integritate (CI). Constrangerile de integritate sunt necesare intr-o baza de date pentru a mentine toate componentele bazei de date in schema. Constrangerile care se refera la o cheie a bazei de date se numesc constrangeri cheie. Constrangerile cheie specifica fiecare cheie candidatpentru fiecare schema relationala din cadrul bazei de date relationale. Exista doua tipuri de constrangeri cheie care sunt parte ale unui model relational:
-entitatea de integritate;
-integritatea referentiala.
Entitatea de integritate defineste care cheie primara nu poate fi nula. Aceasta este necesara deoarece prin cheia primara se individualizeaza fiecare tupla dintr-o relatie. In cazul in care apare valoarea nula (NULL) pentru o valoare acheii primare, tupla nu poate fi individualizata.
Constrangerile de integritate referentiala sunt constrangeri sau restrictii intre doua sau mai multe relatii si sunt folosite sa mentina unitatea tuplelorrelationale. O tupla dintr-o relatie trebuie sa faca referire la o tupla care exista intr-o alta relatie. Pentru definirea conceptului de integritate referentiala este necesara definirea notiunii de cheie externa.
O multime de atribute Fk in relatia R1 este cheie externa a lui R2 daca satisface urmatoarele reguli:
atributele Fk au acelasi domeniu ca si cheia primara a relatiei R2;
valoarea Fk in tupla t1 a lui R1 este identica cu valoarea Pk a unei tuple t2 din R2 deci t1[Fk]=t2 [Pk] si spunem ca tupla t1 face referire la tupla t2.
Relatia R1
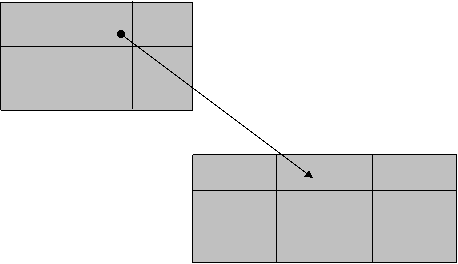
Cheie externa
Relatia R2
Conceptul de cheie externa poate fi aplicatsi la o aceeasi relatie. Grafic, pot fi reprezentate printr-un arc de cerc de la cheie la relatia pe care o refera.
Exista trei operatii de baza care se pot aplica unei relatii:
1. inserarea unei tuple sau a mai multora intr-o relatie;
2. stergerea unei tuple sau a mai multor tuple din aceeasi relatie;
3. modificarea valorilor din domeniul unuia sau a mai multor atribute.
La aplicarea acestor operatii trebuie avut grija sa nu fie incalcate constrangerile de integritate. Exista cateva cazuri in care pot fi incalcate constragerile de integritate referitoare la operatia de inserare:
daca se doreste adaugarea unei tuple la care atributul cheie este identic cu unul deja existent in fisier;
daca se doreste inserarea unei tuple care are campul cheie NULL;
daca la inserarea unei tuple, valoarea atributului sau atributelor cheie externa nu se regaseste in relatia la care face referire cheia externa.
In cazul in care nu este pastrata integritatea bazei de date exista doua cai ce pot fi urmate:
1. Anularea unei comenzi de inserare. DBMS (sistem de gestiune al baei de date) trebuie sa atentioneze acest lucru.
2. Atentionarea unei operatii care distruge integritatea bazei de date si corectarea cauzei care a produs eroarea inainte ca operatia sa devina activa.
In cazul unei operatii de stergere, pot apare disfunctii:
daca se sterge o tupla care contine o cheie externa necesara in referirea mai multor relatii;
daca se sterge o tupla al carei atribut este referit de mai multe chei externe din diferite relatii.
In primul caz, solutia este de a anula stergerea, eventual se poate face corectia necesara, i timp ce in al doilea caz este necesar ca stergerea sa se faca in cascada, adica in toate tuplele relatiilor in care apare valoarea atributului.
Modificarea unui atribut care nu este cheie primara sau cheie externa nu ridica probleme deosebite. Daca o cheie primara este modificata, cazul este similar cu stergerea unei tuple si inserarea alteia in acelasi loc, deoarece se foloseste cheia primara pentru identificare. In acest caz, DBMS trebuie sa verifice daca noua valoare a cheii satisface conditiile de integritate, daca este distincta si poate referi o tupla care exista intr-o relatie sau in mai multe relatii.
Pentru gestionarea bazelor de date este necesara asigurarea unui set de reguli privind corectitudinea datelor. Constrangerile de integritate introduse la nivelul bazelor de date sunt realizate in scopul de a avea certitudinea ca datele existente in bazele de date sunt valide. Implementarea acestor restrictii la nivelul DBMS are avantajul ca regulile raman valabile pentru toate aplicatiile scrise.
Exemple de constrangeri de integritate la nivelul bazelor de date, pentru DBMS care fac parte din familia Xbase sau Oracle:
v NULL impune prezenta sau nu a unei valori intr-un atribut;
v UNIQUE (DISTINCT) impune ca toate valorile dintr-un atribut sa fie diferite;
v PRIMARY KEY desemneaza un atribut sau o multime de atribute drept cheie primara a relatiei;
v REFERENTIAL desemneaza reguli de integritate intre relatii de tip parinte-fiu. Relatia parinte contine cheia referita iar relatia fiu contine cheia externa. Integritatea referentiala stabileste cateva reguli :
S nu se poate elimina sau modifica cheia referita daca cheia rezultata violeaza restrictiile de integritate prin referinta;
S se pot elimina valorile cheii referite daca nu exista nici o legatura dependenta. Daca exista o astfel de dependenta, atunci eliminarea sau modificarea unei valori dintr-o cheie referita la nivel de relatie parinte, o va elimina din toate relatiile fiu existente;
S CHECK constrangerea de integritate pe o conditie care trebuie sa fie adevarata. Pentru a satisface aceasta restrictie, fiecare tupla a relatiei trebuie sa indeplineasca conditia impusa.
| Contact |- ia legatura cu noi -| | |
| Adauga document |- pune-ti documente online -| | |
| Termeni & conditii de utilizare |- politica de cookies si de confidentialitate -| | |
| Copyright © |- 2025 - Toate drepturile rezervate -| |
|
|
||||||||||||||||||||||||
|
||||||||||||||||||||||||
|
||||||||||||||||||||||||
Referate pe aceeasi tema | ||||||||||||||||||||||||
|
| ||||||||||||||||||||||||
|
||||||||||||||||||||||||
|
|
||||||||||||||||||||||||