|






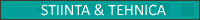 |  |

| Aeronautica | Comunicatii | Drept | Informatica | Nutritie | Sociologie |
| Tehnica mecanica |
Calculatoare
|
|
Qdidactic » stiinta & tehnica » informatica » calculatoare Fiabilitatea in arhitectura calculatoarelor - cresterea fiabilitatii |
Fiabilitatea in arhitectura calculatoarelor - cresterea fiabilitatii
Fiabilitatea in arhitectura calculatoarelor
Cuprins
Introducere
Fiabilitate
Definitie
Redundanta
Erori tranziente si erori permanente
Costul fiabilitatii; sisteme echilibrate
Cresterea fiabilitatii
Evitarea defectelor
Scheme de votare
Procesorul IBM G5 din sistemul S/390
Un procesor superscalar tolerant la erori tranziente
DIVA
Coduri detectoare si corectoare de erori
RAID
Rezumat
Introducere
In acest text voi prezenta arhitectura sistemelor de calcul dintr-un singur punct de vedere, si anume cel al fiabilitatii. Prezentarea nu va fi exhaustiva si nici matematizata; voi folosi mai ales exemple pentru a ilustra cum felurite consideratii despre fiabilitate influenteaza design-ul sistemelor de calcul.
Principalul subiect al teoriei fiabilitatii (reliability theory) este construirea sistemelor fiabile din componente nefiabile. Daca un sistem ar functiona numai atunci toate componentele sale ar fi functionale, ar fi virtual imposibil de construit un sistem complex, pentru ca fiabilitatea ar descreste exponential cu numarul de componente.
Principala unealta folosita in construirea sistemelor complexe este abstractia. Un sistem este construit pe nivele; nivelul B este alcatuit din componente de nivel A. La rindul lor, componente de nivel B sunt folosite ca si cum ar fi atomice, indivizibile, pentru a construi nivelul C, si asa mai departe. Acest proces este inspirat din matematica, unde lemele si teoremele sunt folosite drept componente elementare in demonstratiile altor leme si teoreme. In acest text vom privi alcatuirea unor nivele din arhitectura sistemelor de calcul din punctul de vedere al fiabilitatii pe care o ofera nivelelor superioare. Astfel putem distinge:
1.Nivele care maresc fiabilitatea, construind un tot mai fiabil din componente mai putin fiabile. Acest lucru este obtinut folosind redundanta in stocarea sau calculul informatiei. Acest tip de nivel este cel mai adesea folosit in constructia calculatoarelor contemporane. Sectiunea 3 discuta multe astfel de exemple.
2.Nivele care expun lipsa de fiabilitate nivelelor superioare, lasindu-le pe acestea sa rezolve imperfectiunile. Nivelele superioare au adesea informatii suplimentare despre cerintele reale de fiabilitate ale sistemului, si ca atare pot construi fiabilitate pe masura necesitatilor.
In fine, anumite nivele partitioneaza resursele in parti oarecum independente, izolate una de alta. Partitionarea are drept efect izolarea defectelor (fault containment / fault isolation), astfel incit o defectiune intr-o parte sa nu afecteze celelalte parti. In calculatoare aceasta tehnica este folosita in sistemele de operare si clustere-le de calculatoare.
La ora actuala circuitele integrate pe scara larga (Very Large Scale Integrated circuits, VLSI) au ajuns la nivele incredibile de fiabilitate. Ca atare arhitectii calculatoarelor in general privesc nivelul hardware ca fiind perfect si folosesc aceasta abstractie foarte convenabila in proiectarea nivelelor superioare. Anumite clase de aplicatii insa au nevoie de o fiabilitate foarte ridicata (de exemplu, controlul de trafic aerian sau supervizarea centralelor nucleare). In astfel de sisteme critice arhitectii sistemelor de calcul iau in considerare si posibilitatea defectelor hardware, pe care le trateaza in software.
Miniaturizarea continua a circuitelor integrate va duce la schimbari in aceasta stare de fapt; trebuie sa ne asteptam ca in viitor circuitele sa contina din ce in ce mai multe defectiuni si sa fie din ce in ce mai sensibile la fluctuatii termodinamice si particule de inalta energie din radiatia cosmica sau chiar din degradarea radioactiva a circuitului integrat! Astfel de schimbari vor cere probabil o regindire completa a arhitecturii sistemelor de calcul.
Fiabilitate
In aceasta sectiune vom introduce terminologia folosita in restul articolului.
Definitie
Chiar daca acest text nu este matematic, vom da o definitie precisa a notiunii de fiabilitate.
Fiabilitatea unui obiect (o componenta sau un sistem) este o functie de timp F(t), definita ca probabilitatea ca, in conditii de mediu specificate, obiectul sa functioneze adecvat in intervalul de timp [0,t).
|
Putem face citeva observatii foarte importante legate de aceasta definitie:
Fiabilitatea este o probabilitate, cuprinsa intre 0 si 1.
Nu exista sisteme perfect fiabile, pentru care pentru care F(t) = 1 daca t > 0. Putem insa
vorbi de sisteme destul de fiabile, atunci cind avem in minte anumite conditii de utilizare si constringeri bugetare pentru implementarea sistemului.
Nu putem defini fiabilitatea fara a specifica mediul in care sistemul opereaza. Un calculator care merge foarte bine pe birou nu este neaparat potrivit pe un satelit.
Redundanta
Ingredientul cel mai folosit pentru a construi sisteme fiabile este redundanta. Putem distinge doua genuri de redundanta, spatiala si temporala:
Redundanta spatiala foloseste mai multe componente decit strict necesar pentru a implementa un anumit sistem. Resursele aditionale fac calcule suplimentare si rezultatele sunt comparate intre ele. In general, cu cit redundanta unui sistem este mai mare, cu atit poate detecta sau tolera mai multe erori.
Redundanta temporala consta in folosirea aceluiasi dispozitiv pentru a calcula acelasi lucru in mod repetat, dupa care rezultatele sunt comparate intre ele.
Erori tranziente si erori permanente
Putem clasifica defectele in doua mari categorii:
Erori tranziente sunt erori care se manifesta printr-o malfunctie temporara a unei componente, dar nu prin defectarea ei definitiva. In sistemele de calcul contemporane, cea mai mare parte a erorilor sunt tranziente.
Erori permanente: se produc la un moment dat si persista pina cind sistemul este reparat. In aceasta categorie includem si defectele din fabricatie.
Dupa cum va puteti imagina, redundanta temporala poate fi folosita numai pentru a tolera defecte tranziente. Pentru a tolera efecte permanente trebuie sa avem o forma de redundanta spatiala.
Costul fiabilitatii; sisteme echilibrate
Cind proiectam un sistem complex este foarte important sa echilibram fiabilitatea partilor. De exemplu, daca memoria unui sistem are o fiabilitate mult mai mare decit procesorul, atunci sistemul se va defecta cel mai adesea cu probleme de procesor. Faptul ca memoria este de foarte buna calitate nu ne ajuta cu nimic; dimpotriva, probabil ca am platit un pret mai mare pentru memorie decit ar fi fost strict necesar. In general, o componenta este destul de buna daca nu are cea mai mare probabilitate de defectare.
Intotdeauna cind discutam despre fiabilitate trebuie sa socotim nu numai costul componentelor fiabile, ci si costul intretinerii sistemului. Cit pierdem pe ora atunci cind sistemul nu functioneaza? Daca cumparam componente foarte fiabile platim prea mult pentru constructia sistemului, dar daca cumparam componente cu fiabilitate prea redusa, ne va costa prea mult intretinerea sistemului. Numai contextul poate dicta cit de fiabil trebuie sa fie un sistem: de exemplu, in aplicatiile critice descrise mai sus, costul ne-functionarii sistemului este urias, asa incit are sens sa investim in componente extrem de fiabile.
Cresterea fiabilitatii
In aceasta sectiune voi discuta citeva tehnici folosite pentru a construi sisteme de calcul fiabile.
Evitarea defectelor
Evitarea defectelor este o metodologie idealizata, care presupune ca toate componentele sunt perfecte. Pentru ca hardware-ul de astazi are o calitate exceptionala, nivelul software in calculatoarele obisnuite adopta o astfel de viziune idealizata. Programatorii presupun ca sistemul pe care se ruleaza programele lor este lipsit de defectiuni.
Fiabilitatea excelenta a dispozitivelor hardware este obtinuta printr-o combinatie de tehnici, cum ar fi felurite forme de redundanta, proiectare si fabricatie cu precizie foarte ridicata, si o faza agresiva de testare si ardere (burn-in).
Empiric s-a observat ca sistemele tind sa aiba o mortalitate care urmareste o curba numita albie, ilustrata in figura 1: sistemele foarte tinere si cele foarte uzate se strica mult des decit sistemele mature. Burn-in este o faza de testare care foloseste componentele pina devin mature; in acest fel, componentele cu mortalitate infantila ridicata sunt eliminate.
In plus fabricantii proiecteaza si testeaza sisteme de calcul in conditii mai nefavorabile decit cele specificate. De exemplu, pe acest fapt se bazeaza cei care fac overclocking: specificatiile unui procesor indica frecventa de ceas la care acesta poate opera. Dar in mod frecvent un procesor cu specificatie de ceas de 1Ghz poate opera la 1.2Ghz, datorita marginilor de toleranta din fabricatie.
Figura 1: Graficul ratei de eroare a unui dispozitiv in functie de virsta sa are adesea forma de albie: dispozitivele foarte noi si foarte vechi au o probabilitate mai mare de a se defecta.
|
|
Metoda evitarii defectelor este cu adevarat extrema. In restul acestui text vom vedea metode mai pesimiste, care recunosc ca fiecare din componente se poate defecta si incearca se mentina sistemul in functionare; aceasta paradigma se numeste toleranta defectelor (fault-tolerance).
Scheme de votare
O metoda foarte simpla dar scumpa de a tolera erori este de a multiplica fiecare componenta. De exemplu, daca duplicam intreg sistemul de calcul, aparitia unui defect poate fi detectata comparind rezultatele celor doua subsisteme.
Prima schema de toleranta a defectelor a fost propusa de John von Neumann in 1956 si se numeste redundanta modulara tripla (Triple Modular Redundancy). In aceasta schema trei module fac aceeasi operatie si un modul de vot alege rezultatul majoritar. Daca fiecare componenta are o fiabilitate de peste 50%, fiabilitatea ansamblului este mai mare decit a componentelor. Exista si scheme in care sistemul de votare este replicat, pentru a nu depinde de o singura componenta.
Un astfel de sistem de votare este folosit in calculatoarele care controleaza naveta spatiala: sistemul este compus din cinci calculatoare, din care patru fac aceleasi calcule si al cincilea este folosit pentru operatiuni ne-critice. Rezultatele celor patru calculatoare se duc pina la sistemele controlate (motoare), care calculeaza local rezultatul votului. In plus, fiecare calculator compara rezultatele cu celelalte trei; cind unul dintre ele da rezultate diferite este scos din functiune.
Daca doua calculatoare se defecteaza sistemul intra intr-un mod de functionare in care rezultatele sunt comparate si recalculate cind difera. Al cincilea calculator contine un sistem de control complet separat, dezvoltat de alta companie, care intra in functiune cind un bug identic este detectat in celelalte patru programe .
Procesorul IBM G5 din sistemul S/390
In aceasta sectiune vom discuta un tip de redundanta hibrida, care foloseste redundanta spatiala pentru a detecta erori tranzitorii si redundanta temporala pentru a le remedia. Acest sistem este asemanator cu modul de functionare cu doua defectiuni folosit de naveta spatiala, descris mai sus. Aceasta tehnica e utilizata in multe sisteme comerciale, dar noi vom discuta microprocesorul G5 folosit de compania IBM in calculatoarele sale mainframe.
Microprocesorul G5 contine doua benzi de executie identice, care sunt controlate de acelasi ceas. Toate instructiunile sunt executate in mod sincron de ambele benzi, iar la sfirsitul benzii rezultatele sunt comparate. Daca rezultatele sunt identice, rezultatul instructiunii este scris in registrul destinatie sau in memorie. Daca nu, se genereaza o exceptie software, care de obicei se soldeaza cu re-executia instructiunii-problema. Erorile tranziente sunt astfel reparate in mod transparent. Aceasta schema este functionala pentru ca probabilitatea ca o eroare tranzienta sa afecteze ambele benzi in acelasi fel este foarte foarte mica.
Calculatorul S/390 foloseste redundanta in multe alte feluri: toate sursele de curent, sistemele de racire, discurile, etc., sunt duplicate. Sistemul nu are un singur punct critic. Acesta este deci un sistem echilibrat: ce sens ar avea un microprocesor deosebit de fiabil daca sursa de curent se poate arde adesea?
Un procesor superscalar tolerant la erori tranziente
O schema foarte originala care foloseste doar redundanta temporala pentru a tolera erori tranziente a fost propusa acum cativa ani,in 2001, la conferinta de microarhitectura MICRO 2001 de un grup de cercetatori de la universitatea Carnegie Mellon. In aceasta schema, unui procesor superscalar obisnuit i se fac citeva modificari simple, astfel incit fiecare instructiune citita sa fie lansata in executie in mod repetat. Mecanismele de redenumire a registrilor folosite in procesorul superscalar fac executarea unor instructiuni suplimentare, care nu afecteaza sistemul, un lucru foarte simplu. La sfirsitul benzii de asamblare rezultatele copiilor lansate in executie sunt comparate intre ele. Robustetea depinde de gradul de redundanta: daca fiecare instructiune este executata de doua ori, o eroare se manifesta prin rezultate diferite si instructiunea trebuie re-executata; daca o instructiune este executata de mai mult de doua ori, se poate folosi o schema de votare cu majoritate.
Un astfel de procesor poate fi proiectat sa lucreze fie in mod normal, fie in mod cu fiabilitate crescuta, depinzind de tipul de program executat. Performanta in modul cu fiabilitate ridicata este invers proportionala cu gradul de redundanta; de exemplu, daca fiecare instructiune este executata de doua ori, ne-am astepta la o scadere a vitezei de calcul la 50%. In realitate, penalizarea este ceva mai mica, din cauza ca un program nu foloseste toate resursele computationale. De exemplu, daca un program foloseste 80% din resurse, cind executam programul duplicind fiecare instructiune avem nevoie de 160% resurse, ceea ce se traduce intr-o degradare a performantei cu 37,5% (100/160 = 62,5 = 100 - 37,5).
DIVA
O schema deosebit de interesanta de redundanta spatiala a fost propusa in aceeasi conferinta in 1999 de catre Todd Austin, profesor la universitatea Michigan. Acest proiect e numit DIVA, de la Dynamic Implementation Verification Architecture: arhitectura cu verificare dinamica.
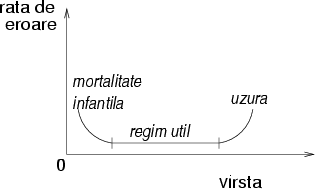
Spre deosebire de schemele anterioare, DIVA e proiectata pentru a tolera atit erori tranziente, cit si permanente (cele din urma doar in anumite parti ale sistemului). Observatia centrala pe care se bazeaza DIVA este ca e mai usor de verificat daca rezultatul unui calcul e corect decit este de efectuat calculul insusi. Ca atare, arhitectura DIVA este compusa din doua procesoare diferite:
Figura 2: Procesorul DIVA este compus dintr-un procesor performant care efectueaza calculele si un procesor lent si foarte robust care le verifica corectitudinea.
|
|
Un procesor complex, superscalar, foarte optimizat, care face calculele in mod normal;
Un procesor extrem de simplu, mai lent, dar foarte fiabil, care executa instructiunile in ordine, si este construit folosind tehnici de evitare a defectelor.
Procesorul DIVA functioneaza astfel:
Procesorul complex executa toate instructiunile si calculeaza rezultatele lor. Rezultatele insa nu sunt scrise, ci sunt transmise procesorului simplu.
Procesorul simplu merge ceva mai incet, si verifica in paralel toate detaliile rezultatelor primite. Desi acest procesor este mai simplu, are o treaba mai usoara, si ca atare poate atinge aceeasi performanta ca cel rapid (exprimata in instructiuni procesate pe secunda). Cind verificarea descopera o eroare, procesorul simplu calculeaza rezultatul corect si re-porneste procesorul complex de la instructiunea urmatoare.
Foarte interesant este ca o arhitectura DIVA poate tolera chiar erori de proiectare in procesorul foarte complicat, pentru ca acestea sunt detectate si corectate de procesorul lent si simplu. Poate fi chiar avantajos ca procesorul rapid sa fie proiectat incorect, dar extrem de rapid, in cazul in care nu produce rezultate eronate prea frecvent. De exemplu, intr-un procesor normal foarte multe circuite suplimentare sunt introduse pentru a trata corect cazul programelor care se auto-modifica. In realitate, practic nici un program modern nu foloseste aceasta tehnica in mod curent; procesorul rapid fara aceste circuite poate fi facut mult mai eficient. Corectitudinea va fi asigurata de procesorul lent.
Coduri detectoare si corectoare de erori
Am vazut deja mai multe exemple de folosire a redundantei spatiale pentru detectarea si corectarea erorilor. Costul schemelor prezentate mai sus este substantial: ele cer o replicare identica a unui intreg sistem. De exemplu, redundanta modulara tripla are o eficienta de 33%, pentru ca hardware-ul este replicat de trei ori.
E interesant de explorat daca nu putem obtine aceleasi beneficii cheltuind mai putine resurse suplimentare. Deschizatori de drumuri au fost in aceasta privinta Claude Shannon si Richard Hamming, spre sfirsitul anilor '40. Vom discuta despre metodele propuse de ei pentru a stoca informatie in mod fiabil.
Sa presupunem ca vrem sa stocam niste informatii codificate in baza doi intr-un mod fiabil. Putem atunci de pilda face doua copii ale informatiei. Dar o defectiune a unui singur bit va face informatia de nerecuperat, pentru ca acel bit va fi diferit in cele doua copii, si nu putem deduce care este valoarea originala. Slabiciunea acestei metode consta in faptul ca bitii stocati nu sunt robusti: fiecare bit din mesaj este reprezentat in doar doi biti din cod. Daca amestecam bitii din mesaj putem face mult mai bine de atit.
Pentru a obtine rezilienta la erori trebuie sa adaugam redundanta in cod; astfel, vom codifica n biti de informatie folosind m > n biti de cod. Cu cit m e mai mare ca n, cu atit mai robust va fi codul nostru. Cuvintele de m biti care reprezinta coduri corecte se numesc ``cuvinte de cod'' (code words). Observati ca nu toate cuvintele de m biti sunt cuvinte de cod, ci numai 2n dintre ele.
Putem defini distanta Hamming intre doua siruri de biti ca fiind numarul de diferente intre cele doua siruri. De exemplu, distanta Hamming dintre 1111 si 1010 este 2, pentru ca cele doua siruri difera in pozitiile a doua si a patra. Cea mai mica distanta Hamming dintre cuvintele unui cod este o masura foarte buna a robustetii codului. De exemplu, daca distanta Hamming intre oricare doua cuvinte este mai mare decit 3, atunci o schimbare de 1 bit poate fi intotdeauna corectata: cel mai apropiat cuvint de cod este cel care a fost modificat de eroare, pentru ca toate celelalte cuvinte de cod se vor afla la o distanta mai mare de 2 de cuvintul eronat. Astfel, un cod cu distanta Hamming 3 poate corecta orice eroare de 1 bit, si poate detecta orice eroare de doi biti. Un astfel de cod va detecta si alte erori, de exemplu va detecta unele erori de trei biti, dar nu orice eroare de trei biti.
Exista efectiv zeci de coduri diferite, fiecare potrivit in alte circumstante. Vom prezenta niste exemple in ceea ce urmeaza.
Memorii
Daca ati cumparat vreodata memorie pentru PC-ul dumneavoastra, v-ati lovit desigur de dilema care tip de memorie trebuie cumparat. Din punct de vedere al fiabilitatii, exista trei tipuri de memorie pe piata: memorii neprotejate, memorii cu paritate si memorii ECC.
Memoriile neprotejate stocheaza fiecare bit de date in mod separat si nu ofera nici o protectie impotriva erorilor. Ca atare sunt cele mai ieftine. Cum insa dimensiunea memoriilor a crescut foarte repede, la ora actuala aceasta solutie este riscanta, caci probabilitatea ca nici un bit sa nu se defecteze este foarte redusa.
Memoriile cu paritate folosesc o metoda foarte simpla pentru a detecta erori de un bit in fiecare octet (si, in general, erori care schimba un numar impar de biti). Pentru fiecare 8 biti de date aceste memorii stocheaza un al noualea bit de paritate, a carui valoare este calculata astfel incit oricare cuvint de noua biti are un numar par de biti 1 (de aici si numele schemei).
Cind hardware-ul acceseaza memoria, automat verifica si paritatea. Daca paritatea nu este corecta se declanseaza o exceptie si sistemul de operare decide cum trebuie sa actioneze. O solutie este de a omori programul care folosea acea memorie si de a marca memoria ca fiind defecta, astfel incit alte programe sa nu o poata refolosi. Verificarea paritatii este o operatie foarte rapida, care se poate face foarte simplu in hardware in paralel cu transferul informatiei.
Memoriile ECC sunt protejate cu un cod sofisticat de corectie a erorilor (Error Corecting Code). Acest cod poate corecta automat orice eroare de 1 bit care apare intr-un cuvint de 64 de biti. Pentru acest scop memoria stocheaza fiecare cuvint de 64 de biti folosind cuvinte de cod de 72 de biti. Observati ca risipa (overhead) acestei scheme este aceeasi cu cea a paritatii (9/8 = 72/64); aceasta schema ofera corectie cu o robustete mai mica, pentru ca poate corecta o eroare la 64 de biti, spre deosebire de cealalta schema care poate detecta o eroare la 8 biti.
La fiecare acces la memorie hardware-ul verifica daca cuvintul de cod este corect; daca nu automat calculeaza cel mai apropiat cuvint de cod pe care apoi il decodifica. Aceste operatii sunt destul de complicate, astfel incit un sistem cu memorii ECC merge cu aproximativ 5% mai lent decit unul cu memorii cu paritate.
Discuri
Cel mai comun suport persistent de informatie este discul, in multiplele lui incarnari: hard disc, discheta, disc optic, compact-disc, etc. Informatiile din aceasta sectiune sunt valabile pentru multe din aceste tipuri de discuri.
Discurile folosesc simultan doua metode diferite de redundanta spatiala; o protectie sporita este necesara din cauza ca discurile functioneaza intr-un mediu mult mai aspru decit memoriile: discurile au parti mecanice in miscare, care se uzeaza si se pot strica mai usor.
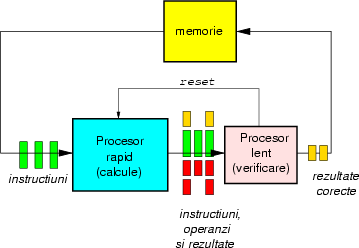
Informatia este stocata pe disc in sectoare. Un sector este relativ mare (comparat cu un cuvint de memorie), fiind de ordinul a jumatate de kilooctet (512 octeti). Discurile folosesc sectoare mari pentru ca la viteza lor de rotatie (peste 5000 de revolutii pe minut) capetele de citire/scriere nu se pot plasa foarte precis pe suprafata. Astfel, unitatea elementara in care se scrie pe un disc este sectorul: chiar daca vrem sa modificam un singur bit, trebuie sa rescriem tot sectorul.
Figura 3: Formatul unui sector de disc: informatia servo este folosita pentru controlul miscarii capului, identificatorul indica numarul sectorului curent, informatia de sincronizare este folosita pentru a sincroniza pozitia capului cu inceputul sectorului; datele sunt stocate intr-un sir compact, codificate folosind un cod detector de erori. Intre doua sectoare consecutive este o gaura, care-i da capului ceva libertate cind rescrie sectorul (niciodata nu va rescrie incepind chiar din acelasi loc).
|
|
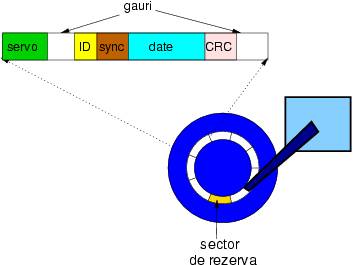
Codurile folosite pentru discuri se numesc CRC, de la Cyclic Redundancy Check: coduri ciclice. Un cuvint de cod consta din chiar cuvintul de date urmat de informatii de control; decodificarea codurilor CRC este foarte simpla: se extrage direct cuvintul de date. Codul de control verifica daca vreunul din bitii stocati e incorect. Un cod ciclic are proprietatea ca orice permutare a datelor este protejata de acelasi cuvint de control.
Cind codul de control indica defectarea unui sector, discurile folosesc in mod automat a doua forma de redundanta spatiala: sectoare de rezerva. Pe disc sunt ascunse sectoare invizibile, care sunt folosite atunci cind sectoarele de date incep sa dea rateuri. In mod transparent software-ul aloca un sector de rezerva in locul unuia defect. Identificatorul de sector este folosit pentru a indica cine pe cine inlocuieste.
Discurile stocheaza o harta de defecte care indica sectoarele inlocuite; asta le permite sa functioneze si dupa ce apar defectiuni, si permite de asemenea un proces de fabricatie mai imperfect si mai ieftin.
Turbo-coduri
Codurile detectoare si corectoare de erori sunt folosite pe larg in retelele de calculatoare. Depinzind de caracteristicile canalului de comunicatii (distanta, cost de transmisiune, viteza semnalului, zgomot) se pot folosi coduri mai mult sau mai putin robuste. In anumite cazuri e preferabil ca erorile sa fie detectate si datele incorecte sa fie retransmise, in alte cazuri costul retransmisiei este prea mare, si ca atare se folosesc coduri corectoare. Folosirea unui cod corector in transmisiunea de date se mai numeste si codare preventiva (Forward Error Correction).
Pentru comunicatia cu sondele spatiale se folosesc coduri corectoare de erori extrem de robuste, pentru ca la astfel de distante semnalul electromagnetic are nevoie de multe minute pentru a se propaga. In 1993 un grup de cercetatori francezi a inventat o clasa de coduri extrem de robuste, numite Turbo-coduri, care folosind o redundanta relativ redusa, de 200% obtin o rezistenta exceptionala la zgomot, fiind foarte aproape de limitele maxime teoretice.
Turbo-codurile ilustreaza un nou tip de compromis pe care arhitectul il poate face in ecuatia robustete/cost: costul cel mare al unui turbo-cod nu este in cantitatea mare de informatie suplimentara, ci in algoritmul de decodificare, care este foarte complicat si necesita multe iteratii. Dupa cum am vazut si in cazul memoriilor, cu aceeasi redundanta putem obtine garantii diferite de fiabilitate, in functie de algoritmul de codificare folosit. In cazul comunicatiei interplanetare costul transmisiunii face costul decodificarii insignifiant, deci turbo-codurile sunt potrivite.
RAID
In aceasta sectiune voi ilustra un alt tip de sistem fiabil redundant, care, spre deosebire de alte solutii prezentate, are o performanta mai buna decit sistemul de baza. In plus, acest sistem adauga o dimensiune noua in spatiul optiunilor fiabilitatii, si anume capacitatea de a fi reparat in timp ce functioneaza (maintainability).
RAID este o prescurtare de la Redundant Array of Inexpensive Disks, sau set redundant de discuri ieftine. Ideea a fost introdusa in 1987 de cercetatori de la universitatea Berkeley din California, si la ora actuala este obiectul unei industrii anuale de 12 miliarde de dolari.
Ideea centrala in RAID este de a stoca informatie pe mai multe discuri simultan. Informatia este codificata redundant, astfel incit sa poata fi recuperata daca oricare din discuri se defecteaza. Aceasta proprietate este foarte utila pentru sisteme care trebuie sa functioneze in foc continuu.
Intr-un sistem RAID toate celelalte tehnici de marire a fiabilitatii opereaza simultan: fiecare disc foloseste coduri CRC si sectoare de rezerva, iar sistemul RAID foloseste stocare a informatiei redundanta.
Exista mai multe tipuri de sisteme RAID, dar aici vom discuta unul singur, in care informatia este scrisa pe 5 discuri, din care 4 contin date si unul paritate.
Un astfel de sistem RAID se poate afla intr-unul din trei moduri de functionare:
Functionare normala: operatiile de citire extrag date de pe cele patru discuri cu date. O operatie de scriere insa stringe patru blocuri de informatie si calculeaza un al cincilea bloc de paritate; fiecare bloc este stocat pe alt disc. Acest mod de scriere se numeste striping, adica feliere, pentru ca datele sunt scrise in paralel, cite o felie pe fiecare disc.
Functionarea degradata: este inceputa cind un disc se defecteaza. Atunci citirile si scrierile de pe discul stricat trebuie sa acceseze celelalte patru discuri si sa calculeze informatia lipsa. Avantajul paritatii este ca oricare din bitii lipsa poate fi recalculat ca paritatea celorlalti patru biti.
Reconstructia: este inceputa cind un disc defect este inlocuit. Un proces secundar recalculeaza informatia lipsa si o scrie pe noul disc.
Rezumat
Fiabilitatea este definita ca fiind probabilitatea ca un sistem sa se defecteze intr-o anumita perioada de timp si in anumite conditii de mediu;
Sistemele de calcul sunt construite din succesiuni de nivele abstracte, care au diferite fiabilitati;
Fiabilitatea unui mecanism poate fi sporita folosind redundanta spatiala sau temporala; redundanta temporala poate tolera efectul unor erori tranziente, pe cind redundanta spatiala poate ascunde si erori permanente;
Un sistem de calcul trebuie sa fie echilibrat din punct de vedere al fiabilitatii: toate nivelele trebuie sa fie comparabile, altfel cel mai nefiabil nivel este veriga cea mai slaba a lantului;
Codurile detectoare si corectoare de erori pot descoperi si repara stricaciuni ale datelor stocate sau transmise folosind grade relativ reduse de redundanta.
Bibliografie : https://www.cs.cmu.edu/~mihaib/
| Contact |- ia legatura cu noi -| | |
| Adauga document |- pune-ti documente online -| | |
| Termeni & conditii de utilizare |- politica de cookies si de confidentialitate -| | |
| Copyright © |- 2025 - Toate drepturile rezervate -| |
|
|
||||||||||||||||||||||||
|
||||||||||||||||||||||||
|
||||||||||||||||||||||||
Referate pe aceeasi tema | ||||||||||||||||||||||||
|
| ||||||||||||||||||||||||
|
||||||||||||||||||||||||
|
|
||||||||||||||||||||||||